Java——Stream流API(一)
本文总结自《Modern Java in Action》(Java 8)
简介
引入
流(
Stream,Java 8出现的新API),它允许以声明性方式处理数据集合(即通过查询语句来表达,而不是临时编写一个实现)。
举一个例子来说明上述流的性质:要求返回低热量(卡路里低于400)的菜肴名称,并按卡路里大小升序排列:
在没有流之前,我们可能会这么写:
1 | List<Dish> lowCaloricDishes = new ArrayList<>(); //首先筛选出第卡路里的菜品 |
咋一看答案很正确、思路很清晰,可读性也不错,但是总觉得有一些复杂,而且还需要一个中间变量容器lowCaloricDishes;在有了Stream流之后,代码将变得非常简洁,如下:
1 | List<String> lowCaloricDishesName =menu.stream() //生成流 |
在上述流的代码中,我们不关心具体内部是如何实现的(实现由内部API帮忙实现了),而更加关心实现的逻辑,相比之下的优势如下:
- 代码是以声明性方式写的:说明想要完成什么而不是说明如何实现一个操作。这种方法加上行为参数化让你可以轻松应对变化的需求:很容易再创建一个代码版本,利用
Lambda表达式来筛选高卡路里的菜肴,而用不着去复制粘贴代码; - 可以把几个基础操作链接起来,来表达复杂的数据处理流水线(在
filter后面接上sorted、map和collect操作,如图所示),同时保持代码清晰可读。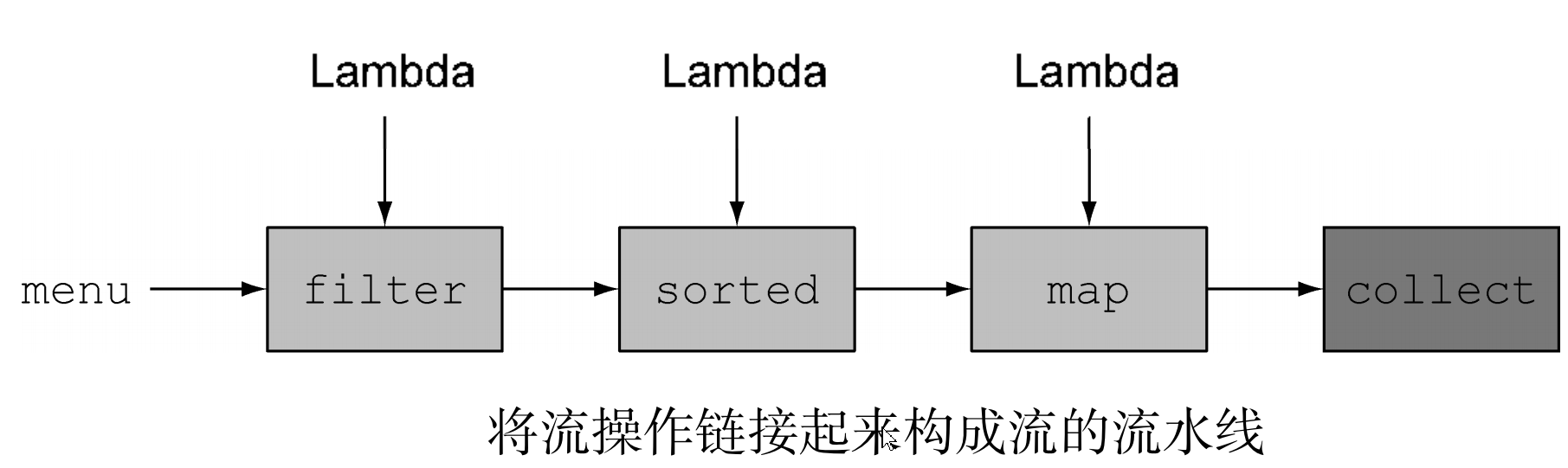
总结一下,Java 8中的Stream可以让你写出这样的代码:
- 声明性——更简洁,更易读;
- 可复合——更灵活;
- 可并行——性能更好(之后篇章介绍)。
概念
流到底是什么呢?通过上述案例,我们可能对流有了一点点模糊的印象,现在我们来看定义:从支持数据处理操作的源生成的元素序列:
- 元素序列——就像集合一样,流也提供了一个接口,可以访问特定元素类型的一组有序值。因为集合是数据结构,所以它的主要目的是以特定的时间/空间复杂度存储和访问元素。但流的目的在于表达计算,比如你前面见到的
filter、sorted和map。集合讲的是数据,流讲的是计算; - 源——流由一个提供数据的源生成,如集合、数组或输入/输出资源。 从有序集合生成流时会保留原有的顺序;
- 数据处理操作——流的数据处理功能支持类似于数据库的操作,以及函数式编程语言中的常用操作(如
filter、map、reduce、find、match、sort等),流操作可以顺序执行,也可并行执行。
此外,流操作有两个重要的特点:
- 流水线——很多流操作本身会返回一个流,这样多个操作就可以链接起来,形成一个大的流水线;
- 内部迭代——与使用迭代器显式迭代的集合不同,流的迭代操作是在背后进行的。
现在借助一段代码增强理解:
1 | List<String> threeHighCaloricDishNames = menu.stream() //从menu中获取流 |
具体操作顺序如下:
- 先是对menu调用
stream方法,由菜单得到一个流(数据源是菜肴列表,它给流提供一个元素序列); - 接下来,对流应用一系列数据处理操作:
filter、map、limit和collect。除了collect之外,所有这些操作都会返回另一个流,这样它们就可以接成一条流水线,于是就可以看作对源的一个查询; - 最后,
collect操作开始处理流水线,并返回结果。
具体流程图: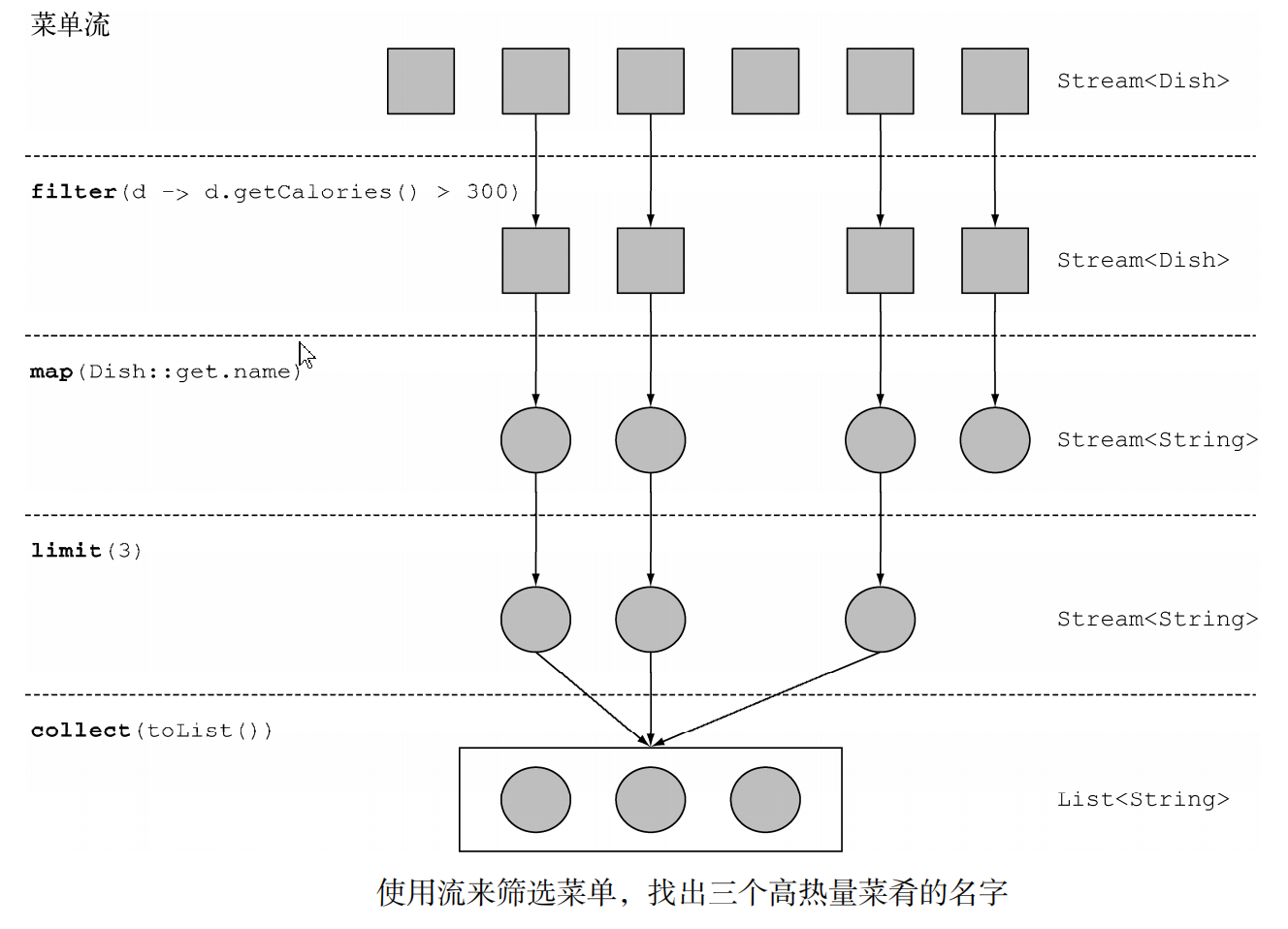
接下来再通过一个比喻来区别集合与流,并加强对流的理解:比如看一部电影,你将电影下载到本地,那么存在本地的电影就相当于集合;或者你也可以选择在线观看,此时的电影可以看做是一个流(字节流或帧流),播放器只需提前下载用户观看位置的那几帧即可,这样不用等到流中大部分值计算出来、将整部电影缓存完成才能看,不然等待时间就太长了。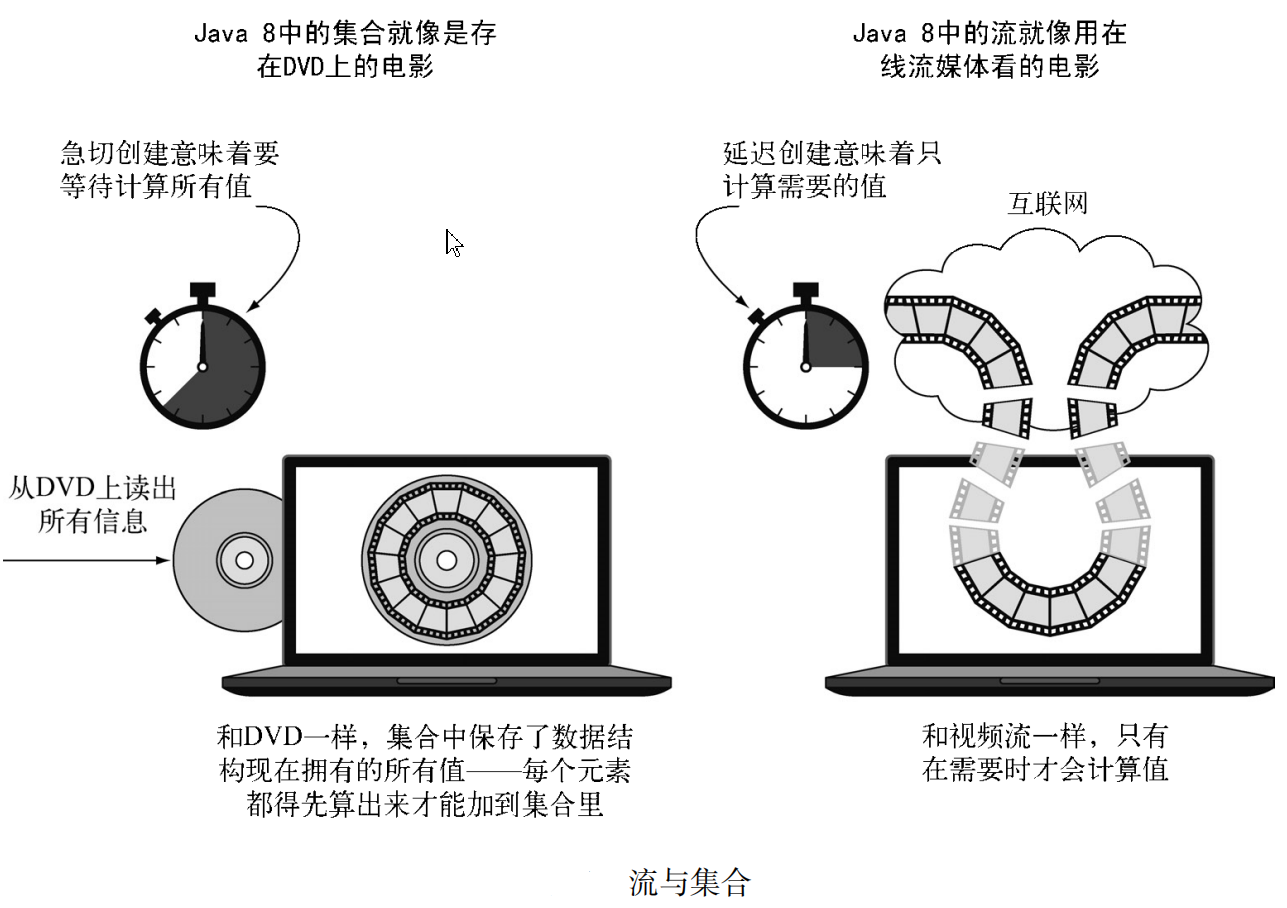
流操作
包含中间操作和终端操作两部分,可以连接起来的流操作称为中间操作,关闭流的操作称为终端操作。1
2
3
4
5List<String> names = menu.stream()
.filter(d -> d.getCalories() > 300)
.map(Dish::getName)
.limit(3)
.collect(toList()); //终端操作,其余均为中间操作
用图来看: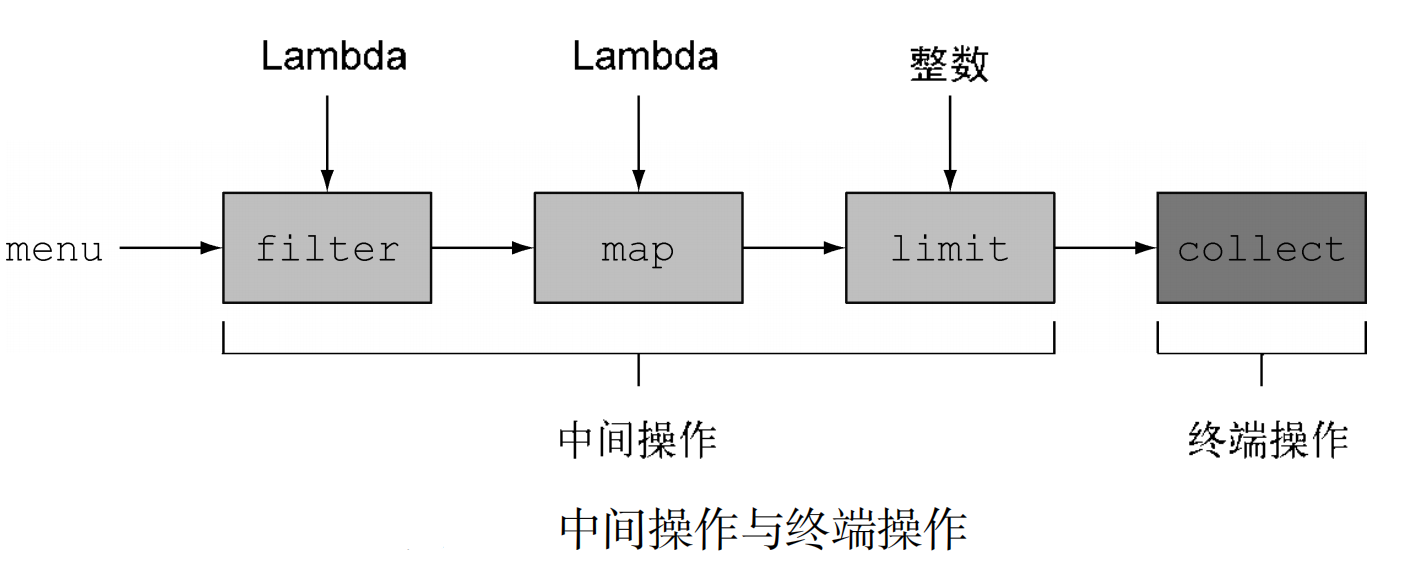
中间操作
中间操作会返回另一个流,这让多个操作可以连接起来形成一个查询。(注:除非流水线上触发一个终端操作,否则中间操作不会执行任何处理,这是因为中间操作一般都可以合并起来,在终端操作时一次性全部处理)
用一段代码来看一下流水线的具体操作:
1 | List<String> names = |
1 | filtering pork |
不难发现中间操作并不是隔开单独进行的,先是通过了filter操作后才可进行下一步的map,而由于limit操作,我们并未将集合中所有元素全部遍历,由此提高了效率。
终端操作
终端操作会从流的流水线生成结果。其结果是任何不是流的值,比如List在这里插入代码片、Integer,甚至void。
流的使用
流的使用一般包括三件事:
- 一个数据源(如集合)来执行一个查询;
- 一个中间操作链,形成一条流的流水线;
- 一个终端操作,执行流水线,并能生成结果。
下表中枚举了一些中间操作和终端操作:
中间操作
| 操作 | 返回类型 | 操作参数 | 函数描述符 |
|---|---|---|---|
filter |
Stream |
Predicate |
T -> boolean |
map |
Stream |
Function |
T -> R |
limit |
Stream |
||
sorted |
Stream |
Comparator |
(T, T) -> int |
distinct |
Stream |
终端操作
| 操作 | 目的 |
|---|---|
forEach |
消费流中的每个元素并对其应用 Lambda。 |
count |
返回流中元素的个数。 |
collect |
把流归约成一个集合。 |
注意事项
和迭代器类似,流只能遍历一次,遍历完之后,我们就说这个流已经被消费掉了。1
2
3
4List<String> title = Arrays.asList("Java8", "In", "Action");
Stream<String> s = title.stream();
s.forEach(System.out::println);
s.forEach(System.out::println); //将报错,流只能遍历一次
案例代码
1 | //案例类Dish |
1 | //数据 |