Java——Stream流API(二)
本文总结自《Modern Java in Action》(Java 8)
本文所用案例代码见博客底部
使用
筛选和切片
对数据进行筛选操作。
筛选:
filter方法,接受一个谓词(一个返回boolean的函数)作为参数,并返回一个包括所有符合谓词的元素的流。
例:在菜单中筛选出所有素菜1
2
3List<Dish> vegetarianMenu = menu.stream()
.filter(Dish::isVegetarian) //isVegetarian是Dish类中判断是否如为素菜的函数
.collect(toList());去重:
distinct的方法,去除重复元素,它会返回一个元素各异(根据流所生成元素的hashCode和equals方法实现)的流。
例:查看菜单中食物种类1
2
3
4List<Dish.Type> dishType = menu.stream()
.map(Dish::getType)
.distinct() //去重,根据hashCode和equals方法判断是否相同
.collect(toList());切片:
limit(n)方法,该方法会返回一个不超过给定长度n的流;skip(n)方法,返回一个去掉前n个元素的流。 配合使用完成切片功能。
例:查询菜单中热量排名第二至第四的食物1
2
3
4
5List<Dish> res = menu.stream()
.sorted(Comparator.comparing(Dish::getCalories).reversed()) //排序
.skip(2) //跳过第一第二
.limit(2) //截取
.collect(toList());
映射
一个非常常见的数据处理方式就是从某些对象中选择信息。比如在SQL里,你可以从表中选择一列,Select语句。StreamAPI也通过map和flatMap方法完成相似操作。
对流中每一个元素应用函数:
map方法,它会接受一个函数作为参数。这个函数会被应用到每个元素上,并将其映射成一个新的元素(使用映射一词,是因为它和转换类似,但其中的细微差别在于它是创建一个新版本而不是去修改)。
例:达到所有菜品的菜名1
2
3List<String> dishNames = menu.stream()
.map(Dish::getName) //将之前的Dish流转换成String流
.collect(toList());注:上述
map操作将一个Stream<Dish>转变成Strean<String>,转变后流的类型与map参数函数的返回类型相关。流的扁平化,让我们先通过一个例子来看,
例:对于一张单词表,如何返回一张列表,列出单词表中各不相同的字符呢?例如,给定单词表["Hello","World"],返回列表["H","e","l", "o","W","r","d"]
首先我们可能想到的第一个解决方案是这样的1
2
3words.stream()
.map(word -> word.split(""))
.distinct()但是这个操作返回的是一个
Stream<String[]>流,我们并得不到想要的答案。
对于一个数组我们可以通过Arrays.stream()方法将其转变为一个流,现在可能得到我们的第二个解决方案1
2
3
4words.stream()
.map(word -> word.split(""))
.map(Arrays::stream)
.distinct()但是此时仍然不是正确答案,因为这个操作返回的是一个
Stream<Stream<String>>流,这时我们发现了Stream的嵌套类型,由此可以引出flatmap方法,正如标题所说——流的扁平化,我们通过这个方法将使用map(Arrays::stream)时生成的单个流合并起来,扁平化为一个流,即将上述Stream<Stream<String>>扁平化为Stream<String>,由此得到结果,此时得到我们的最终解决方案1
2
3
4
5List<String> uniqueCharacters = words.stream()
.map(w -> w.split(""))
.flatMap(Arrays::stream)
.distinct()
.collect(Collectors.toList());下方流程图说明了使用flatMap方法的效果
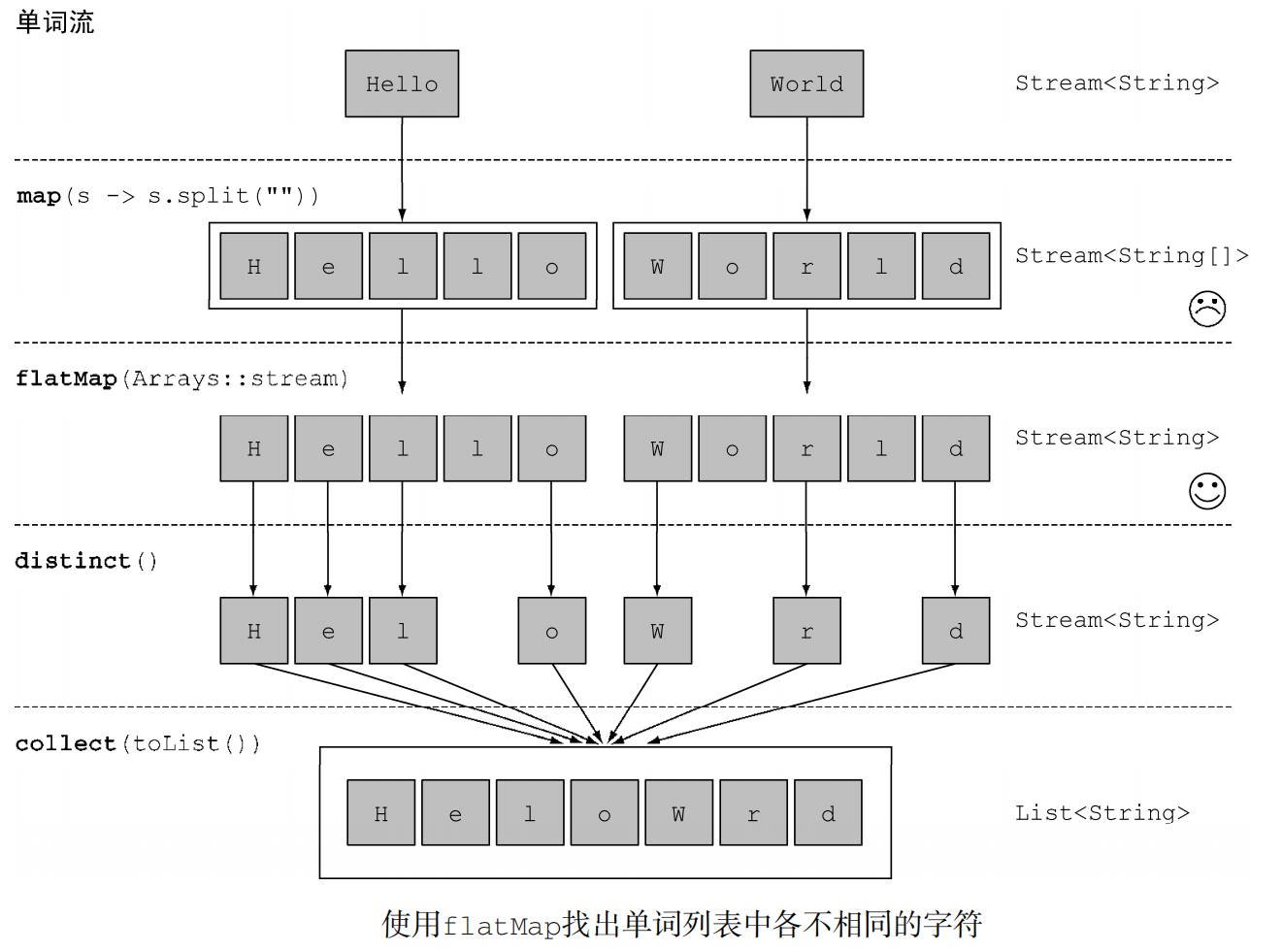
一言以蔽之,flatmap方法将一个流中的每个值都换成另一个流(此步操作与map相同),在此基础上将所有的流连接起来成为一个流,扁平化。
下面通过一个例子对flatmap进行加深理解
给定两个数字列表,如何返回所有的数对呢?例如,给定列表[1, 2, 3]和列表[3, 4],应该返回[(1, 3), (1, 4), (2, 3), (2, 4), (3, 3), (3, 4)]。1
2
3List<Pair<Integer, Integer>> ans = list1.stream()
.flatMap(i -> list2.stream().map(j -> new Pair<>(i, j)))
.collect(Collectors.toList());查找和匹配
另一个常见的数据处理套路是查询数据集中的某些元素是否匹配一个给定的属性。
接下来是三个方法——allMatch、anyMatch、noneMatch是检索流中是否存在满足条件的项,根据前缀意义来判断用途区别,返回boolean值,均为终端操作。
检查谓词是否至少匹配一个元素,
anyMatch方法。
例:可用于检索菜单里面是否有素食1
2
3if(menu.stream().anyMatch(Dish::isVegetarian)){
System.out.println("The menu is (somewhat) vegetarian friendly!!");
}检查谓词是否匹配所有元素,
allMatch方法,是否全部满足
例:检索菜品是否有利健康(即所有菜的热量都低于1000卡路里)1
2boolean isHealthy = menu.stream()
.allMatch(d -> d.getCalories() < 1000);与之对应的是
noneMatch方法,检索是否全部都不满足条件
上述例子的另一种写法1
2boolean isHealthy = menu.stream()
.noneMatch(d -> d.getCalories() >= 1000);扩展:上述三个终端操作,
anyMatch、allMatch和noneMatch这三个操作均用到了所谓的短路,这就是大家熟悉的Java中&&和||运算符短路在流中的版本。即部分条件能够确定表达式的值后将不再继续运算,计算方式从前往后。
接下来是两个方法——findAny、findFirst用于查找流中满足条件的项,根据后缀意义判断用途区别,返回boolean值,均为终端操作。
查找元素,
findAny方法将返回当前流中的任意元素,即返回元素是不确定的,在数据较少,串行地情况下,一般会返回第一个结果,如果是并行的情况,那就不能确保是第一个。
例:找到一个素菜1
2
3Optional<Dish> dish = menu.stream()
.filter(Dish::isVegetarian)
.findAny();- 查找第一个元素,
findFirst方法,查找第一个满足条件的元素,用法与findAny相同。
扩展:
- 上述操作的返回类型——
Optional,Optional<T>类是一个容器类,代表一个值存在或不存在。在上面的代码中,findAny或findFirst可能什么元素都没找到。Java 8的库设计人员引入Optional<T>,这样就不用返回众所周知容易出问题的null了,可通过get()方法取出容器中的元素。 findAny与findFirst的对比:首先findAny方法返回的元素是不确定的,而findFirst返回的就是满足条件的第一个元素。显而易见,找到第一个元素在并行上限制更多,如果不关心返回的元素是哪个,请使用findAny,因为它在使用并行流时限制较少。
归约
一系列终端操作的类型:如何把一个流中的元素组合起来,使用reduce操作来表达更复杂的查询,比如计算菜单中的总卡路里或菜单中卡路里最高的菜是哪一个。此类查询需要将流中所有元素反复结合起来,得到一个值,比如一个Integer。这样的查询可以被归类为归约操作(将流归约成一个值)。用函数式编程语言的术语来说,这称为折叠(fold),因为你可以将这个操作看成把一张长长的纸(你的流)反复折叠成一个小方块,而这就是折叠操作的结果。
元素求和,对于此操作,我们在没有
Stream前,将会通过外部迭代来得到结果1
2
3
4
5int sum = 0; //外部迭代
for (int x : numbers) {
sum += x;
}
int sum = numbers.stream().reduce(0, (a, b) -> a + b); //内部迭代numbers中的每个元素都用加法运算符反复迭代来得到结果。通过反复使用加法,你把一个数字列表归约成了一个数字。
而对于流操作,reduce接受两个参数:
(1)一个初始值,这里是0;
(2)一个BinaryOperator<T>来将两个元素结合起来产生一个新值,这里我们用的是lambda (a, b) -> a + b。
注:若没有给出初始值,是求数字之和会给出默认初始值0,乘法默认初始值为1。并且表达式的返回类型不再为int,而是Optional<Integer>。(考虑流中没有任何元素的情况,reduce操作无法返回其和,因为它没有初始值,而利用Optional容器对象,可表明其和可能不存在。)
这样就很容易得到推广,元素之积1
int product = numbers.stream().reduce(1, (a, b) -> a * b);
下图很好地展现了元素求和的过程
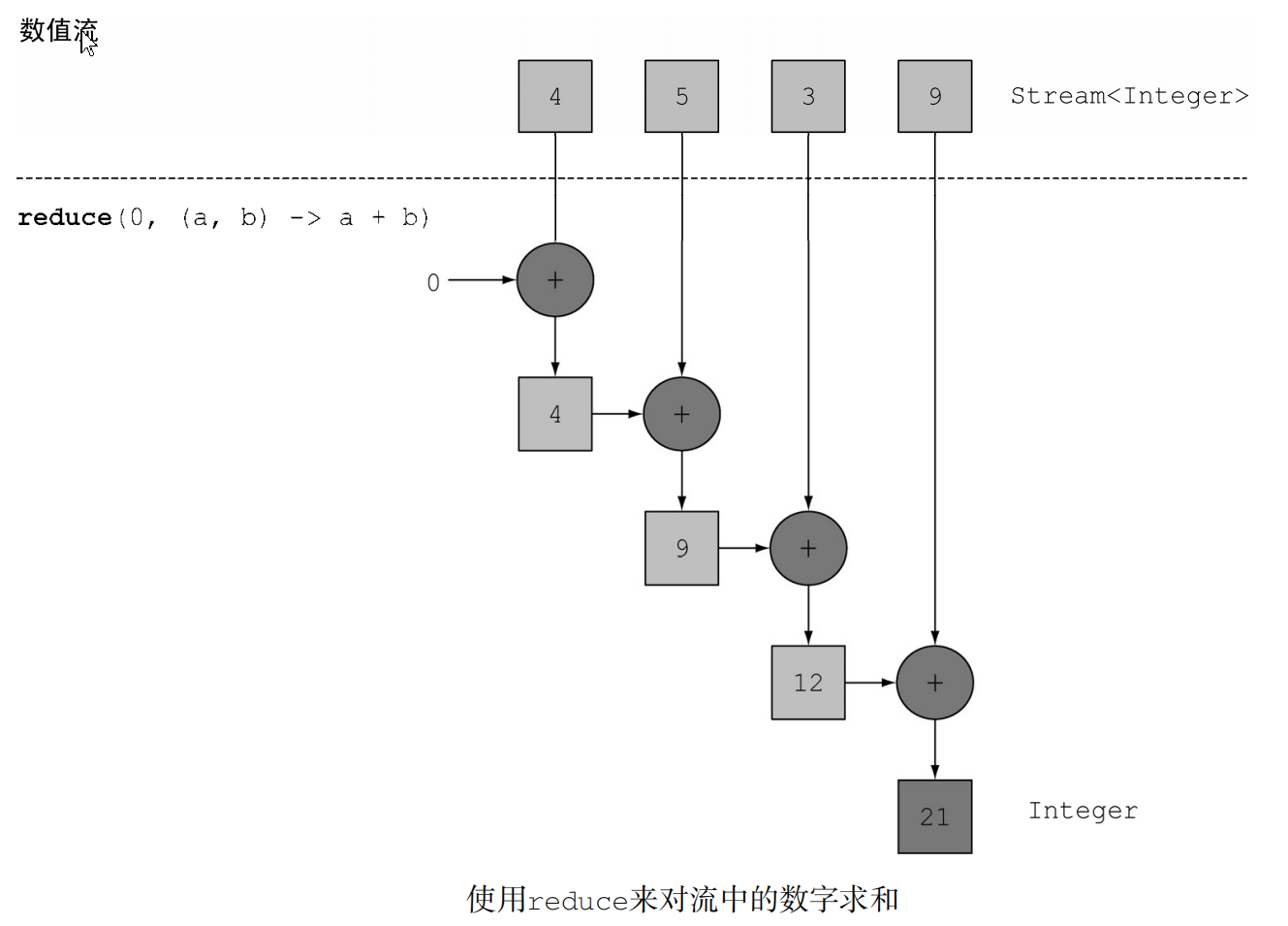
扩展:在Java 8中,Integer类现在有了一个静态的sum方法来对两个数求和,用不着再手打一段Lambda代码了,进行了化简:1
int sum = numbers.stream().reduce(0, Integer::sum);
还可用于求流中的最大值和最小值:
1
2Optional<Integer> max = numbers.stream().reduce(Integer::max);
Optional<Integer> min = numbers.stream().reduce(Integer::min);数值流
在上文归约中使用
reduce方法计算流中元素的总和,我们设计到的流是Stream<Integer>,而最终结果为int,这不难理解整个过程中暗含装箱成本,每个Integer都必须拆箱成一个原始类型,再进行求和。Java 8引入了三个原始类型特化流接口来解决这个问题:IntStream、DoubleStream和LongStream(即数值流),分别将流中的元素特化为int、long和double,从而避免了暗含的装箱成本。原始类型流特化
IntStream、DoubleStream和LongStream中每个接口都带来了进行常用数值归约的新方法,比如对数值流求和的sum,找到最大元素的max,此外还包含数值流与对象流之间的转换方法。映射到数值流:将流转换为特化版本的常用方法是
mapToInt、mapToDouble和mapToLong。这些方法和前面说的map方法的工作方式一样,只是它们返回的是一个数值流,而不是Stream<T>。1
IntStream intStream = numbers.stream().mapToInt(Integer::intValue);
- 转换回对象流:上述方法的逆方法,将数值流转换回对象流。
1
Stream<Integer> IntegerStream = intStream.boxed();
默认值
OptionalInt:与之前reduce提及的Optional<T>相似,为了解决在列表为空时找不到正确答案的问题。1
2
3
4OptionalInt max = numbers.stream()
.mapToInt(Integer::intValue)
.max();
int max = maxCalories.orElse(1); //在没找到正确答案时设置默认值数值范围:数值流提供两个方法
range、rangeClosed,用来生成范围内的数值流。注:range包头不包尾;rangeClosed头尾均包含在内。1
2IntStream evenNumbers = IntStream.rangeClosed(1, 100)
.filter(n -> n % 2 == 0);
构建流
由值创建流
可以使用静态方法Stream.of,通过显式值创建一个流。它可以接受任意数量的参数。
1 | Stream<String> stream = Stream.of("Java 8 ", "Lambdas ", "In ", "Action"); |
由数组创建流
可以使用静态方法Arrays.stream从数组创建一个流。它接受一个数组作为参数。
1 | int[] nums = {2, 3, 5, 7, 11, 13}; |
注:若数组为基本类型(int、double、long),则返回对应的数值流IntStream等;而对于引用类型如String则返回对象流Stream<String>。
由文件生成流
由函数生成流:创建无限流
Stream API提供了两个静态方法来从函数生成流:Stream.iterate和Stream.generate。这两个操作可以创建所谓的无限流:不像从固定集合创建的流那样有固定大小的流。
迭代,直接看代码
1
2
3
4Stream.iterate(0, n -> n + 2) //接受一个初始值(在这里是0)
// 还有一个依次应用在每个产生的新值上的Lambda
.limit(10)
.forEach(System.out::println);大体逻辑就是在一个初始值的基础上,通过Lambda函数不断迭代出新值,然后更新初始值,不断循环往复的过程。
生成,直接上代码
1
2
3Stream.generate(Math::random)
.limit(10)
.forEach(System.out::println);相对于迭代而言它没有了初始值,
generate是不依赖与表达式生成的上一个数值,而是生成一个完全由Lambda生成的新值。
注:为了避免暗含的装箱成本,生成无限流可直接使用数值流完成,如下:1
2
3
4
5IntStream.iterate(0, n -> n + 2)
.limit(10)
.forEach(System.out::println);
IntStream ones = IntStream.generate(() -> 1);在
Stream.generate方法中传入的Lambda表达式是无法保存状态的,为了解决这一个问题(如生成斐波那契额数列),这里可以考虑实现IntSupplier接口中定义的getAsInt方法显式传递一个对象,它可以通过字段定义状态,而状态又可以用getAsInt方法来修改,下面就看一下这个求斐波那契数流例子:
1 | IntStream.generate(new IntSupplier() { |
当然使用Stream.iterate方法会方便一些:
1 | Stream.iterate(new int[]{0, 1}, t -> new int[]{t[1], t[0] + t[1]}) |
总结
下表总结了迄今为止学过的操作。
| 操作 | 类型 | 返回类型 | 使用的类型/函数式接口 | 函数描述符 |
| :————-: | :————————-: | :—————-: | :———————————: | :———————: |
| filter | 中间 | Stream<T> | Predicate<T> | T -> boolean |
| distinct | 中间(有状态-无界) | Stream<T> | | |
| skip | 中间(有状态-无界) | Stream<T> | long | |
| limit | 中间(有状态-无界) | Stream<T> | long | |
| map | 中间 | Stream<R> | Function<T, R> | T -> R |
| flatmap | 中间 | Stream<R> | Function<T, Stream<R>> | T -> Stream<R> |
| sorted | 中间(有状态-无界) | Stream<T> | Comparator<T> | (T, T) -> int |
| anyMatch | 终端 | boolean | Predicate<T> | T -> boolean |
| noneMatch | 终端 | boolean | Predicate<T> | T -> boolean |
| allMatch | 终端 | boolean | Predicate<T> | T -> boolean |
| findAny | 终端 | Optional<T> | | |
| findFirst | 终端 | Optional<T> | | |
| forEach | 终端 | void | Consumer<T> | T -> void |
| collect | 终端 | R | Collector<T, A, R> | |
| reduce | 终端(有状态-有界) | Optional<T> | BinaryOperator<T> | (T, T) -> T |
| count | 终端 | long | | |